참고
Mono / IL2CPP (+ Generic Sharing)
참고 영상 유니티 엔진의 구조유니티 프로젝트를 빌드하다 보면 Project Settings > Player 메뉴에서 Scripting Backend가 있다. 보통 개발 중엔 빠른 빌드를 위해 Mono를 쓰고, 스토어 출시 때는 IL2CPP를 쓴다
tae-woong.tistory.com
0. 서론
지난 글에서 [ECS]로 데이터를 정리하고, [Job System]으로 멀티 코어를 활용하는 법을 정리했다.
이것만으로도 이미 엄청난 성능 향상을 얻었지만, 아직 코드는 C# (Managed Code) 이라는 언어의 태생적 한계 안에 갇혀 있다.
유니티는 이 마지막 리미터를 해제하기 위해 Burst Compiler를 제공한다.
이번 글에서는 Burst가 기존 컴파일러(Mono, IL2CPP)와 어떻게 다르며, 어떤 원리로 CPU의 잠재력을 100% 끌어내는지 기술적으로 파헤쳐 본다.
1. 유니티 컴파일러의 진화 : Mono vs IL2CPP vs Burst
Burst를 이해하려면 유니티가 코드를 처리하는 방식의 흐름을 알아야 한다.
1) Mono (JIT / Development Standard)
- 방식 : C# 코드를 IL(Intermediate Language)로 빌드하고, 게임 실행 시점에 mono VM에서 JIT(Just-In-Time) 컴파일러가 기계어로 변환한다.
- 특징 : 빌드 속도가 빨라 개발 중 주로 사용합니다. 실행 시점에 변환하는 오버헤드가 있어 최상의 성능을 내기는 어렵다.
2) IL2CPP (AOT / Shipping Standard)
- 방식 : C#의 IL 코드를 C++ 코드로 변환한 뒤, 플랫폼별 네이티브 컴파일러(Xcode, NDK 등)를 통해 기계어로 미리 만들어 둡니다. (AOT 방식 : Ahead-Of-Time)
- 특징 : Mono보다 성능이 좋고 보안이 우수하다. 하지만 C#의 안전성(가비지 컬렉션, 널 체크 등)을 유지하기 위해 생성된 C++ 코드에 안전장치가 많이 붙어 있어, 순수 C++보다는 느릴 수 있다.
3) ★ Burst Compiler (AOT / The High-Performance)
- ★ 방식 : C#의 IL 코드를 입력받지만, C++로 바꾸지 않는다. 대신 LLVM이라는 고성능 컴파일러 인프라를 사용해 곧바로 최적화된 기계어로 변환한다.
- ★ 특징 : 범용적인 C# 기능(클래스, 박싱 등)을 포기하는 대신, 수학적 연산과 데이터 처리에서는 인간이 짠 C++보다 더 빠른 코드를 생성해낸다.
2. Burst의 내부 구조 : IL → IR → Machine Code

Burst가 강력한 이유는 전 세계적으로 검증된 컴파일러 기술인 LLVM을 사용하기 때문이다.
IL2CPP는 C++ 코드를 거치지만, Burst는 LLVM을 통해 C++ 단계를 건너뛰고 바로 최적화된 기계어로 간다.
- C# to IL : 우리가 작성한 C# 코드는 먼저 .NET의 중간 언어인 IL로 변환된다.
- IL to IR (Intermediate Representation) : Burst는 이 IL을 LLVM이 이해할 수 있는 중간 표현(IR)으로 변환한다.
- IR이란? 특정 CPU 아키텍처에 종속되지 않은, 컴파일러가 분석하기 가장 좋은 형태의 논리적인 코드다.
- Optimization (IR ↔ IR) : 위 그림의 화살표가 순환하는 구간이다. LLVM Optimizer가 IR 코드를 수십 번 뜯어고치며 불필요한 연산을 제거하고 성능을 극한으로 끌어올린다.
- Machine Code : 최적화가 끝난 IR은 타겟 CPU(Intel, ARM 등)에 맞는 기계어(Assembly)로 최종 변환된다.
3. 핵심 최적화 기술 : SIMD (Single Instruction, Multiple Data)
Burst를 쓰는 가장 큰 이유는 SIMD(심드) 최적화 때문이다.
이는 소프트웨어 기술이 아니라, 현대 CPU 하드웨어에 내장된 물리적인 기능을 100% 활용하는 것이다.
1) 스칼라(Scalar) 처리 vs 벡터(Vector) 처리
현대 CPU 내부에는 일반적인 레지스터(32bit/64bit) 외에, 128bit(SSE/NEON) 혹은 256bit(AVX) 크기의 거대한 벡터 레지스터가 존재한다.
- Scalar (SISD) : 기존 방식이다. 32bit float 변수 하나를 처리하기 위해 128bit 레지스터의 일부만 쓴다. (나머지 공간 낭비)
- ★ Vector (SIMD): 128bit 레지스터에 float (32bit) 4개를 꽉 채워서 한 번에 처리한다.
2) 성능 차이의 원리
4쌍의 데이터 (총 8개 숫자)를 더해야 한다고 가정해보자. (A+B, C+D, E+F, G+H)
- SISD (Single Instruction, Single Data) : 명령 하나에 데이터 하나.
- Load A, Load B, Add (1 Cycle)
- Load C, Load D, Add (1 Cycle)
- Load E, Load F, Add (1 Cycle)
- Load G, Load H, Add (1 Cycle)
- 총 4 Cycle 소요.
- ★ SIMD (Single Instruction, Multiple Data) : 명령 하나에 데이터 뭉치.
- Vector Load [A,C,E,G], Vector Load [B,D,F,H]
- Vector Add (단 1 Cycle!) → 결과: [A+B, C+D, E+F, G+H]
- 단 1 Cycle 만에 4번의 덧셈을 완료한다.
4. 자동 벡터화 (Auto-Vectorization) : Burst가 하는 일
"그럼 개발자가 SIMD 어셈블리어를 직접 짜야 하나?" 아니다.
여기서 Burst Compiler의 자동 벡터화 기술이 빛을 발한다.
1) 반복문(Loop) 분석 및 재조립
우리가 C#으로 평범한 for 루프를 짰을 때, Burst는 이를 다음과 같이 분석하고 개조한다.
- 개발자의 C# 코드 : Burst는 이 코드를 보고 "어? i번째 계산이 i+1번째 계산에 영향을 주지 않네? (독립적)" 라고 판단한다.
for (int i = 0; i < Length; i++) { Result[i] = A[i] + B[i]; } - Burst가 변환한 로직 (개념적):
// 4개씩 묶어서 처리 (SIMD) int i = 0; for (; i <= Length - 4; i += 4) { Vector4 vA = LoadVector(A, i); // A[i] ~ A[i+3] 로딩 Vector4 vB = LoadVector(B, i); // B[i] ~ B[i+3] 로딩 StoreVector(Result, i, vA + vB); // 4개 덧셈을 한방에 처리 } // 남은 자투리 처리 for (; i < Length; i++) { ... }
2) 증거 확인 : Burst Inspector


실제로 변환된 코드는 Burst Inspector에서 확인할 수 있다.
우리가 만든 코드가 fadd 즉, 4개의 합 연산을 한꺼번에 처리할 수 있는 SIMD 어셈블리 명령어로 만들어 진 것을 볼 수 있다.
5. 구현 : HPC# (High Performance C#)
Burst가 이렇게 마음 놓고 코드를 뜯어고칠 수 있는 이유는 HPC# 이라는 제약 조건 때문이다.
HPC# (High Performance C#) 제약 조건을 지키는 코드, 즉 앞서 배운 ECS와 Job System과 완벽하게 결합될 때 작동한다.
- 참조 타입 금지 (No Class) : 클래스는 힙 메모리 어디에나 존재할 수 있어 주소가 불분명하다(Aliasing 문제). 반면 struct와 NativeArray는 메모리 주소가 연속적이고 명확하다.
- 연속된 메모리 (Linear Memory) : 앞서 배운 [ECS] 덕분에 데이터가 일렬로 서 있다. Burst는 "다음 데이터 4개 가져와!"라고 자신 있게 CPU에 명령할 수 있다.
1) Job 정의와 Burst 적용
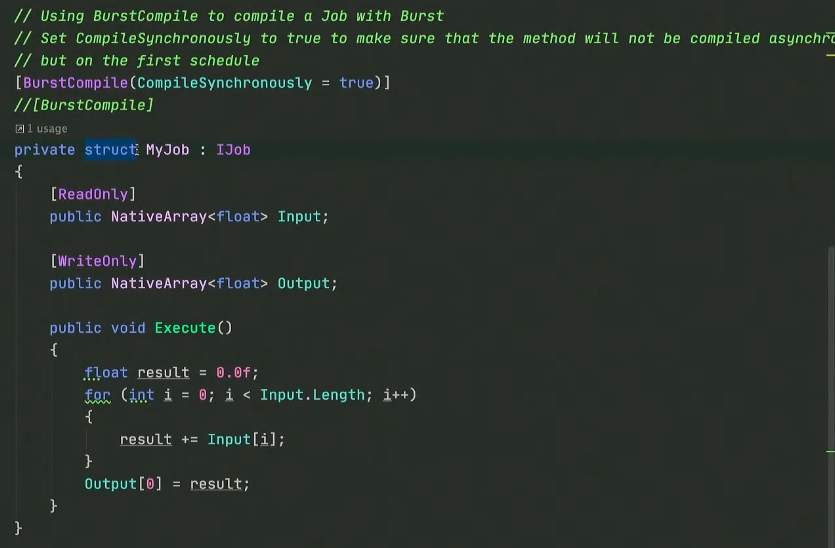
- [BurstCompile] : 이 Job을 Burst로 컴파일하겠다고 선언하는 어트리뷰트다. Unity.Burst 패키지가 필요하다.
- CompileSynchronously = true: 에디터에서 플레이할 때 즉시 컴파일하여, 디버깅을 용이하게 하는 옵션이다.
- struct MyJob : IJob : Burst는 반드시 값 타입(struct)이어야 한다.
- NativeArray : 관리 힙(GC)을 쓰지 않는 네이티브 메모리를 사용하여 Burst가 메모리에 직접 접근할 수 있게 한다.
2) 실행 및 메모리 관리

- 개발자는 job.Schedule()을 호출하여 작업을 예약한다.
- 내부적으로 Burst에 의해 최적화된 기계어 코드가 워커 스레드 위에서 실행된다.
- 작업이 끝나면 Dispose()를 통해 메모리를 해제한다. (HPC#은 GC를 쓰지 않으므로 수동 관리가 필수다.)
6. 결론 : 최후의 가속기
정리하자면, ECS + Job System + Burst Compiler의 시너지는 다음과 같다.
- ECS : 데이터가 메모리에 예쁘게 모여 있다. (SIMD가 데이터를 한 번에 긁어가기 딱 좋은 상태)
- Job System : 여러 스레드가 동시에 작업을 수행한다. (멀티 코어 활용)
- Burst Compiler : 각 스레드가 수행하는 작업을 자동 벡터화(SIMD) 하여, 한 번에 4개, 8개씩 처리해버린다. (하드웨어 가속)
이 3박자가 맞물릴 때, 유니티는 기존 객체 지향 방식으로는 상상할 수 없었던 압도적인 퍼포먼스를 보여준다.
'유니티 > 개념' 카테고리의 다른 글
| Job System : 멀티스레딩과 잡 시스템의 효율성 비교 (0) | 2026.01.04 |
|---|---|
| [Unity DOTS] 5. Synergy (Performance Trinity) (0) | 2026.01.03 |
| [Unity DOTS] 3. Job System (Multithreading) (0) | 2026.01.03 |
| [Unity DOTS] 2. ECS (The Core) (0) | 2026.01.03 |
| [Unity DOTS] 1. OOP vs DOTS (0) | 2026.01.03 |